Differentiated Modeling
Context
In modling theory, classes share the same representation space (parameterization) and the same kind of modeling. But they can be differentiated behind separate representation spaces and distinct statistical models.
For example, note that the differences in production between Word and Music are found naturally in the signal nature themselves: the speech presents a formant structure, while the music shows a harmonic structure. In speech, consonants and vowels do not have the same spectral structure.
Overview
The idea is not to find parameters that discriminate the classes at best but rather to find sets of representation that characterize each class at best. Each class is determined by its representation space, ie. his model:
1 class = {Representation space, Model/class, Model/non class}
This approach can be used in classification using one model for the “non class” and a step of information fusion.
Phonetic Differentiated Modeling
Here is an example of a system that model N languages acoustic spaces represented by CS and VS: the Phonetic Differentiated Model (PDM).Considering phones that share the same acoustic space in a homogeneous model is more efficient than put heterogeneous phones in a unique model.
In this approcah, only two phone classes are considered for acoustic modeling: the vocalic phones (forming Vocalic System) and the non vocalic ones (forming consonant system CS). So, for each language, a VS model and a CS model is defined to compose the “phonetic differentiated model” (PDM) of the language. Gaussian Mixture Model (GMM) is applied to evaluate both VS and CS.
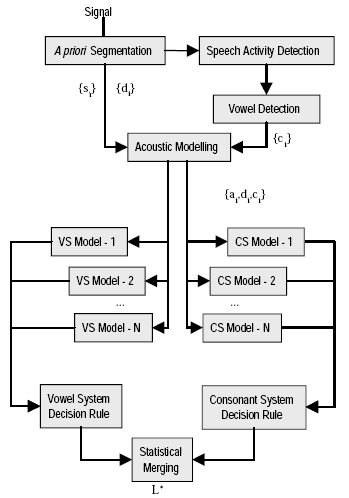
Figure 1. Block diagram of the Phonetic Differentiated Model system. The upper part represents the acoustic
preprocessing and the lower part the language dependent Vowel-System and Consonant-System Modeling.
The PDM system (see figure 1) is composed of:
- A statistical segmentation of the speech in long steady units and short transient ones. The “Forward-Backward Divergence” algorithm is applied.
- A vowel detection
- A cepstral analysis performed on each non silent segment
- A decision procedure resulting of the combination of maximum likelihoods provided by the language-dependent GMMs
The principe can be enhanced with a more precise sub-space modling in order th achieve to better statistical modeling
Speech/music modeling
When studying speech and music, significant differences of production may be observed: speech is characterized by a formantic structure, whereas music is characterized by a harmonic structure. The differentiated modeling is thus completely adapted to our problem. We have defined two sets (cf. figure 2):
- Speech set, S = {Cepstral space, Speech model, Non-Speech model},
- Music set, M = {Spectral space, Music model, Non-Music model}.
The speech preprocessing consists of a cepstral analysis according to Mel scale. The soundtrack is decomposed in frames of 10ms. For each frame, 26 parameters are used: 12 MFCC plus energy and their associated derivatives. The cepstral features are normalized by a cepstral subtraction. For music, a simple spectral analysis is made on the same frames. So, an acoustic feature vector of 29 parameters is computed: 28 filters outputs and the energy. The distribution of filters is placed on a linear frequency scale. For each set, we chose to model the Class (Speech or Music) and the Nonclass (Non-Speech or Non-Music) by a Gaussian Mixture Model (GMM).

Applications
- Automatic Language Identification: At the phonological level, languages could be efficiently classified according to their vowel systems. At the acoustic level, considering phones that share the same acoustic space in a homogeneous model is more efficient than put heterogeneous phones in a unique model: the modeling of voiceless fricatives and vowels in a unique model is less efficient than using separate (or differentiated) models. Moreover if a model is defined for each phone class, specific rules (for example the limits of vocalic spaces) may be used.
- Music/Speech classification: the discrimination speech/music is made with class/non class modeling with two different parametric spaces associated: spectral space for music and cepstral space for speech.
Contributors
Main publications
- Jérôme Farinas, François Pellegrino, Régine André-Obrecht. Automatic Language identification: from a phonetic differentiated model to a complete system. In: Workshop on Friendly Exchanging through the Net, COST 254’2000, Bordeaux, 23/03/00-24/03/00, C. Germain, E. Grivel and O. Lavialle, ENITA/ENSERB, Bordeaux, France, p. 97-102, march 2000.
- Julien Pinquier, Christine Senac, Régine André-Obrecht. Speech and music classification in audio documents. In: International Conference on Acoustics, Speech and Signal Processing (ICASSP’2002), Orlando, USA, IEEE Signal Processing Society, may 2002.